

Trong những giai đoạn đầu 2026, khi toàn bộ thị trường Crypto đang tỏ rõ sự chậm chạp khi hiệu suất Bitcoin không còn tốt. Trong lĩnh vực AI, mọi người đang nói về Claude CodeOpenclaw thay vì những mô hình AI phi tập trung thì hệ sinh thái Bittensor lại khiến cộng đồng chú ý đến. Lần này là Templar - một Subnet trên Bittensor đã hoàn thành một đợt huấn luyện LLM phi tập trung lớn nhất lịch sử với 72 tỷ tham số. Điều này mang lại ý nghĩa như thế nào và tác động của Templar đến thị trường, hãy cùng Hak Research tìm hiểu chi tiết trong bài viết này nhé
Trước khi vào bài viết, mọi người có thể tham khảo một số bài viết sau để hiểu thêm về thị trường Crypto nhé
- Phân tích dTAO: Khi tham vọng phi tập trung trở thành con dao hai lưỡi
- Phân tích Tensorplex: Hệ sinh thái toàn diện trên Bittensor
Tổng Quan Về Templar
Templar là Subnet 3 trên Bittensor do Omega Labs vận hành được thiết kế để huấn luyện các mô hình ngôn ngữ lớn (LLM). Thông thường, để huấn luyện một AI như GPT-4, người ta cần hàng chục nghìn GPU đặt trong cùng một trung tâm dữ liệu, kết nối bằng cáp quang siêu tốc để dữu liệu truyền qua lại tức thì. Trong khi đó, Templar lại làm điều ngược lại:
- Huy động nguồn lực phân tán: Thay vì một siêu máy tính, Templar gom nhiều máy tính đơn lẻ của người dùng khắp thế giới
- Cơ chế mảnh ghép: Mỗi máy chủ (Miner) nhận một phần nhỏ của bộ dữ liệu để học. Sau khi học xong, chúng gửi kết quả học tập (Gradient) về để ghép lại thành một bộ não lớn hoàn chỉnh
Vậy sẽ có một vấn đề được đưa ra: Nếu người tham gia đến từ khắp nơi trên thế giới, họ không tin tưởng lẫn nhau và có độ trễ mạng không ổn định thì làm thế nào để chúng ta có thể đảm bảo kết quả đào tạo là hiệu quả? Làm thế nào để chúng ta có thể ngăn chặn mọi người lười biếng hoặc gian lận? Làm thế nào chúng ta có thể khuyến khích mọi người đóng góp liên tục?
Câu trả lời nằm ở chính cách thức vận hành của mạng lưới Bittensor đó là sử dụng Token TAO làm phần thưởng. Đối với Templar, người nào có chỉ số Gradient càng hiệu quả (chỉ số này có thể hiểu đơn giản là để đo lường sự đóng góp vào việc cải thiện mô hình), họ càng nhận được nhiều TAO. Một điểm đặc biệt là hệ thống tự động chấm điểm và thanh toán, không cần đến bất kì tổ chức tập trung nào điều phối. Nếu Bitcoin đã chứng mình rằng mô hình tài chính phi tập trung là khả thi thì Templar đang viết nên một trang mới chứng minh rằng huấn luyện mô hình AI phi tập trung cũng khả thi
Cách Thức Vận Hành Của Templar
Mạng lưới Templar hoạt động dựa trên sự phối hợp của 3 thực thể chính:
1. Miner (Người huấn luyện): Họ sẽ chịu trách nhiệm truyền tải dữ liệu, thực hiện tính toán và gửi kết quả
Quy trình hoạt động của Miner diễn ra như sau:
- Tải một phần dữ liệu huấn luyện từ bộ nhớ Cloundflare R2
- Huấn luyện mô hình trên dữ liệu đó để tìm ra các Gradient (các chỉ số giúp mô hình học tốt hơn)
- Nén các Gradient này lại (để gửi đi nhanh hơn) và tải chúng lên kho lưu trữ
- Tải xuống các Gradient từ các Miner khác để cập nhật mô hhinfh của chính mình
2. Validator (Người kiểm định): Nhiệm vụ chính là đánh giá chất lượng công việc của Miner
Quy trình hoạt động của Validator diễn ra như sau:
- Thu thập các Gradient mà các Miner đã tải lên
- Chạy thử nghiệm để xem nếu áp dụng các Gradient này thì mô hình có thông minh hơn không
- Chấm điểm Miner dựa trên hiệu quả thực tế
- Ghi điểm số này lên Blockchain Bittensor để hệ thống phát triển
3. Hệ thống lưu trữ (Cloudflare R2)
Vì các File mô hình và dữ liệu Gradient rất nặng, Templar không lưu trữ trực tiếp trên Blockchain mà dùng Cloundflare R2 để lưu trữ giúp việc trao đổi thông tin diễn ra với tốc độ cao hơn
Ngoài ra, để mô hình huấn luyện trở nên hiệu quả vì hệ thống máy tính và cơ sở mạng lưới thông thường vốn chậm hơn rất nhiều so với siêu máy tính và mạng lưới nội bộ đi kèm nên Templar sử dụng hai kĩ thuật then chốt:
- Nén Gradient: Vì gửi toàn bộ dữ liệu huấn luyện qua Internet là bất khả thi vì quá nặng nên Templar sẽ chuyển dữ liệu sang dạng tần số (giống như cách nén ảnh JPEG), chỉ giữ lại những phần quan trọng nhất của dữ liệu và bỏ qua các phần nhiễu. Điều này giúp giảm băng thông cần thiết mà vẫn giữ được độ chính xác của việc huấn luyện
- Cơ chế tính điểm OpenSkill: Thay vì chỉ chấm điểm đơn giản, Templar sử dụng mô hình OpenSkill (tương tự như hệ thống xếp hạng Elo trong Game). Nếu Miner gửi kết quả giúp mô hình cải thiện vượt bậc, thứ hạng của họ tăng mạnh. Điều này tạo ra một cuộc đua công bằng nơi chỉ những người có phần cứng tốt và thuật toán tối ưu mới nhận được phần thưởng cao nhất
Về quy trình huấn luyện được chia thành các Window (khoảng thời gian cố định, khoảng 7 Block)
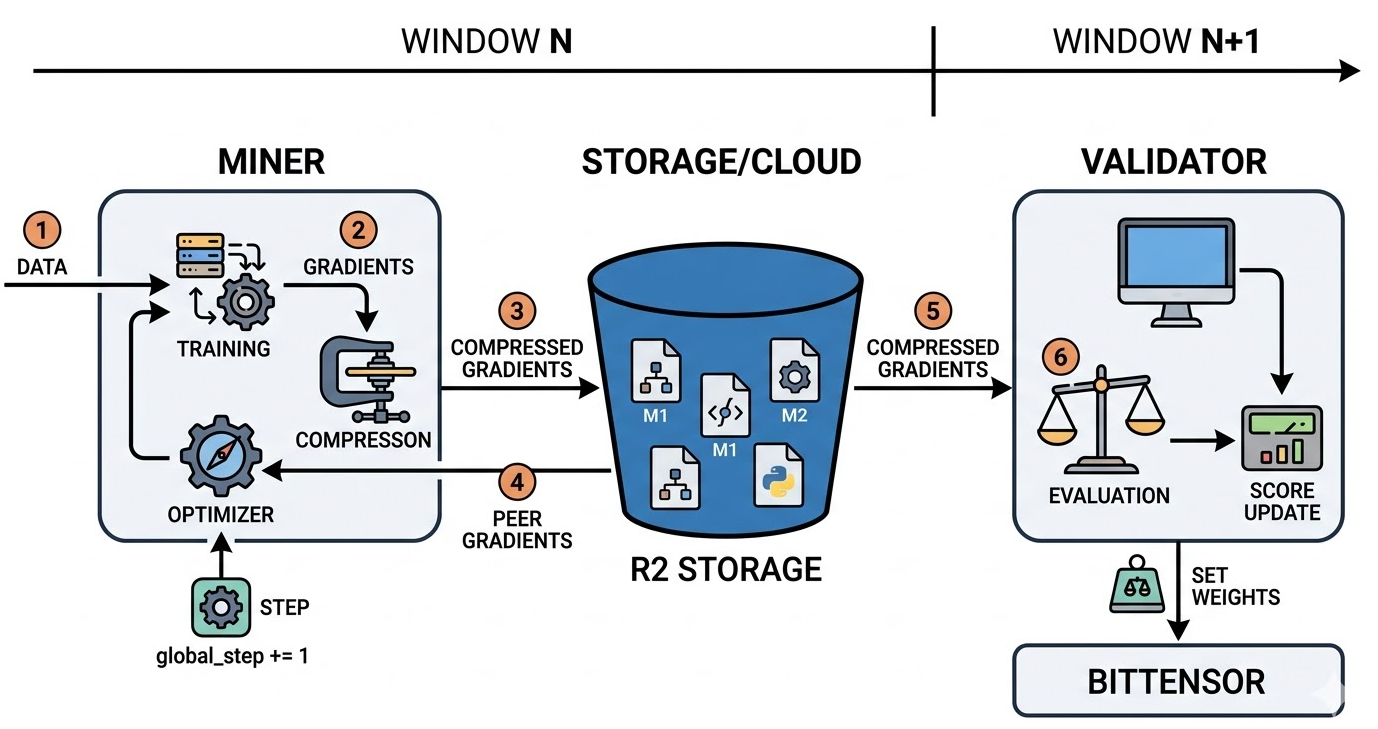
- Bắt đầu Window: Miner xác định mình cần học dữ liệu nào
- Huấn luyện: Miner chạy máy tính để tạo ra Gradient
- Giao tiếp: Miner đẩy Gradient lên Clound, Validator kéo xuống chấm điểm
- Cập nhật: Cả mạng lưới cùng cập nhật mô hình lên một trạng thái tốt hơn
- Lặp lại: Sang Window tiếp theo
Templar Đã Đạt Được Những Thành Tựu Gì?
Vào ngày 10/03/2026, Templar thông báo hoàn thành quá trình huấn luyện cho một mô hình LLM có tên là Covenant -72B. Vậy điều này nghĩa là gì?
Covenant-72B nghĩa là Templar đã hoàn thành 72 tỷ tham số hiểu đơn giản các tham số này như Nơ ron thần kinh của bộ não và mô hình AI nào càng nhiều tham số thì mô hình càng thông minh. Để so sánh với các mô hình AI tập trung hiện tại thì GPT-3 có 175 tỷ tham số, GPT-4 có 1800 tỷ tham số, Mistral Large 2 có 123 tỷ tham số, LLaMA-2 có 70 tỷ tham số
Điểm đặc biệt là chỉ có hơn 70 Miner tham gia đóng góp sức mạnh tính toán và quá trình huấn luyện bắt đầu vào ngày 12/09/2025 tức là đến thời điểm hiện tại là 6 tháng nhưng chúng ta đã có Covenant - 72B mặc dù nó vẫn chưa thể so sánh với các mô hình AI tập trung hiện đại nhất ở thời điểm hiện tại nhưng đây đã là thành công cực lớn đối với mô hình AI phi tập trung nơi cộng đồng có thể góp sức để tạo nên các mô hình AI thực sự mạnh chứ không chỉ dành cho các công ty lớn như hiện nay
Để so sánh mức độ trí tuệ của Covenant-72B so với các mô hình AI tập trung cùng tham số như LLaMa-2 thì Templar đã cho Covenant-72B thực hiện các bài kiểm tra trí tuệ phổ biến đã cho thấy sự vượt trội hơn so với các mô hình AI tập trung này
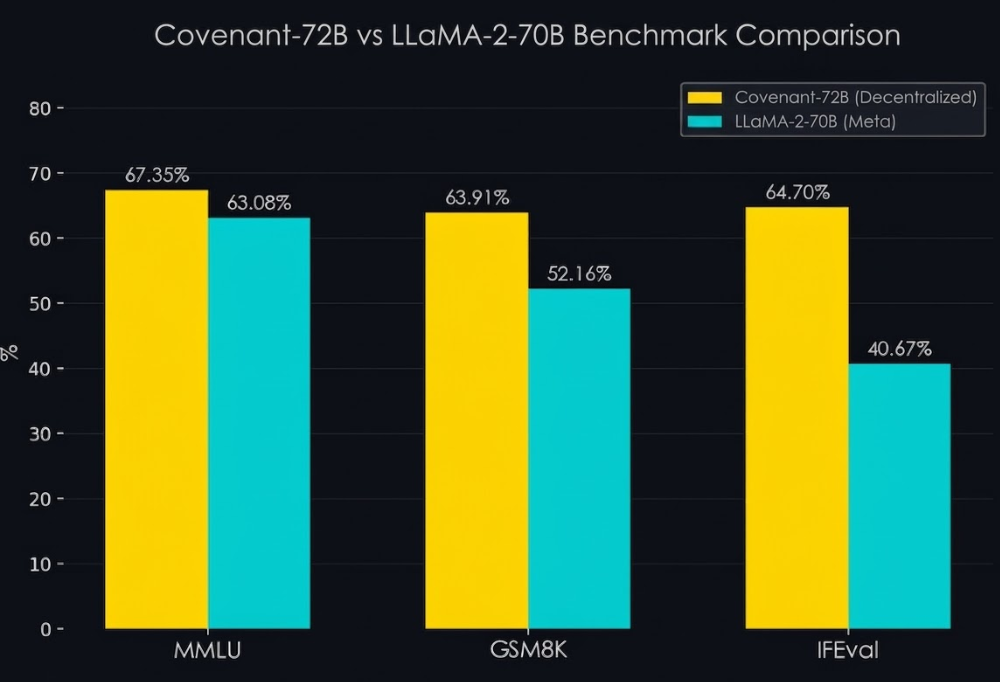
Ví dụ trên MMLU, Covenant-72B đạt 67.1 cao hơn LLaMA-2-70B (65.6), điều này cho thấy khả năng hiểu ngôn ngữ đa nhiệm và kiến thức tổng quát của Covenant-72B đã tốt hơn LLaMA-2. Hay với IFEval, Covenant-72B đạt 64.7% cao hơn nhiều so với LLaMA -2 chỉ đạt 40.67%, đây là điểm nhấn lớn nhất vì IFEval đo lường khả năng tuân thủ các hướng dẫn cụ thể. Việc hơn LLaMA tới 24% chgo thấy mô hình AI này cực kì nhạy bén trong việc hiểu và làm theo ý muốn của người dùng
Tuy nhiên nếu so sánh với các mô hình AI đang được sử dụng phổ biến hiện nay như Qwen 2.5 của Alibaba Clound hay LLaMA 3 của Facebook thì Covenant-72B vẫn đang bị thua xa khi nếu xét về MMLU thì Qwen 2.5 đạt 86.8% trong khi LLaMA 3 đạt 83.6%. Tại sao lại có khoảng cách lớn đến vậy?
Rõ ràng Qwen 2.5 hay LLaMA 3 được hậu thuẫn bởi nguồn lực tài chính cực lớn, hàng vạn GPU H100 kết nối siêu tốc và đội ngũ kĩ sư tinh hoa nhất trong ngành làm việc tập trung. Trong khi đó Covenant-72B được ghép nối từ hơn 72 Miner độc lập, sử dụng băng thông Internet dân dụng và không có trung tâm điều phối. Tuy nhiên khoảng cách này không phải thất bại mà cho thấy tiềm năng phát triển cực kì mạnh mẽ trong tương lai, nếu hiện tại với nguồn lực phân tán mà đã đạt 67% so với 86% thì khi mạng lưới Bittensor được mở rộng hơn thì khoảng cách này sẽ sớm bị san lấp
Tác Động Đến Bittensor Và Ngành AI Phi Tập Trung
Sự thành công của Covenant-72B là một bước ngoặt đáng chú ý. Trước đây, việc huấn luyện các mô hình thuộc lớp 70B là lĩnh vực độc quyền của một vài tập đoàn lớn do rào cản về vốn và năng lực tính toán. Covenant-72B lần đầu tiên chứng minh rằng một cộng đồng, không cần bất kì nguồn tài trợ tập trung nào có thể huấn luyện một mô hình có quy mô tương đương.
Hiện tại, bối cảnh các mô hình AI nền tảng đang tập trung cao độ vào các tập đoàn lớn như OpenAI, Google, Meta và Anthropic nơi họ kiểm soát các mô hình mạnh nhất. Tính khả thi của việc đào tạo phi tập trung đồng nghĩa với việc rào cản này không phải là không thể vượt qua. Sự thành công của Covenant-72B đã định nghĩa lại lai được phép tham gia vào việc phát triển mô hình AI nền tảng
Thành công của Templar cũng mở ra những khả năng hoàn toàn mới cho hệ sinh thái Bittensor. Hiện tại, Bittensor đã có hơn 79 Subnet đang hoạt động trải rộng trên nhiều lĩnh vực khác nhau từ đào tạo AI, truy xuất dữ liệu, điện toán bảo mật, y sinh học,... Khi đặt Bittensor trong bối cảnh rộng hơn của ngành công nghiệp trí tuệ nhân tạo, hiện tại mức định giá của Bittensor đang là 2.5B, chỉ chiếm khoảng 11.5% trong lĩnh vực Crypto AI. Nếu tương lai của AI đòi hỏi các mạng lưới huấn luyện mở, không cần cấp phép thì cơ sở hạ tầng duy nhất đã được kiểm chứng trong thực tế là Bittensor.
Tổng Kết
Templar đang chứng minh một luận điểm quan trọng: huấn luyện AI phi tập trung không còn là lý thuyết mà đã có thể triển khai thực tế ở quy mô lớn. Dù vẫn tồn tại khoảng cách với các mô hình AI tập trung hàng đầu, thành tựu của Templar cho thấy tiềm năng mở rộng của Bittensor trong việc dân chủ hóa hạ tầng AI. Nếu tiếp tục tối ưu mạng lưới và mở rộng quy mô, Bittensor có thể trở thành lớp hạ tầng cốt lõi cho xu hướng AI phi tập trung trong tương lai

.png)
.png)
.png)

.png)
.png)
Top Latest Articles

SolRouter Là Gì? Giải Pháp Suy Luận Trí Tuệ Nhân Tạo Bảo Mật Trên Solana
SolRouter là gì? SolRouter là một lớp suy luận Trí Tuệ Nhân Tạo bảo đảm quyền riêng tư được xây dựng trên mạng lưới Solana, cho phép người...

.png)
.png)
